Introduction
DeepSeek V4 has finally arrived after much anticipation. Just hours ago, the preview version was released and open-sourced. Coincidentally, OpenAI also launched GPT-5.5 on the same day. One focuses on a closed-source productivity system, while the other emphasizes open-source, long context, and low-cost inference. The two largest foundational model companies in the AI industry of China and the US met on the same day.
DeepSeek V4 comes in two versions: Pro and Flash, both supporting a million (1M) tokens of ultra-long context, with total parameter scales of 1.6T (activated 49B) and 284B (activated 13B), respectively.

However, beyond the impressive figures of “1.6T parameters” or “one million token context,” two numbers in the technical documentation deserve more attention: 27% and 10%.
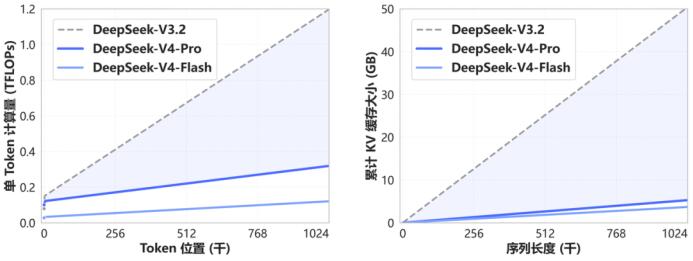
According to the introduction of the V4 series on HuggingFace, under the one million token context scenario, the single token inference FLOPs of V4-Pro is only 27% of V3.2, and the KVcache is only 10% of V3.2.
In simpler terms, in scenarios dealing with ultra-long materials, V4 not only “fits in” but also runs faster and is cheaper.
This may be the most noteworthy aspect of the V4 update.
In the past six months, long context has become a common selling point for leading models. Claude, Qwen, Kimi, and GLM have all been moving towards long text, code repositories, and agent tasks, while DeepSeek has focused on the most costly aspects of long text scenarios: computation and caching.
Unfortunately, V4 currently lacks native multimodal capabilities, which limits its performance in certain scenarios.
Thus, the keyword for V4 is not the long-awaited “new species” in the industry, but rather a further step in “efficiency engineering.”
Faster, but No Native Multimodal
In 2026, it is no longer surprising for large models to support long contexts. However, another question arises: can the model continue to work efficiently when processing ultra-long texts and chains?
If a model only looks at a few paragraphs of text, answering questions is not difficult; but if it needs to review an entire code repository, dozens of contracts, or months of meeting records, and continuously generate, retrieve, modify code, and call tools, the difficulty increases exponentially.
The single token inference FLOPs of V4-Pro is only 27% of V3.2, and the KVcache is only 10% of V3.2, which directly addresses this issue.
The former indicates the computational load required to generate each token, while the latter refers to the KVcache usage, which can be understood as the “working memory” the model needs to carry when processing long texts.

The longer the text, the heavier this working memory becomes; if the model carries the full burden at every step, it becomes difficult to remain agile.
Therefore, speed is paramount.
Here, speed does not refer to a few seconds faster in a chat window, but rather the operational efficiency in long text tasks. After processing 1M text, can the model still function effectively and support high-frequency calls?
This point is also reflected in the newly launched GPT-5.5, where many ChatGPT users have noted that the response speed of GPT-5.5-Thinking has improved significantly.
With the current popularity of agent workflows, this metric becomes even more critical. System-level agent tools, including OpenClaw, often need to read files, check information, call tools, modify code, save intermediate states, and continue to the next step based on feedback.
The more realistic the task and the longer the context, the more the computational and caching burden can snowball. Many agent products today seem futuristic, but when it comes to costs, they resemble disasters. If V4 can indeed reduce operational efficiency under long contexts, it could impact the cost structure of the entire agent toolchain.
We conducted a simple offline test with DeepSeek V4Pro, running two scenarios close to everyday user experiences.
First, we provided V4 Pro with a set of materials about MCP, structured output, tool invocation, edge models, and inference services to write a technical analysis. This task primarily tested whether the model could organize a bunch of concepts and terms into a clear engineering diagram.
V4Pro performed like a seasoned technical editor. It did not reiterate the materials point by point but grasped a main line: the competition among agents is not just about model parameters but also about how models can stably integrate with external systems. In other words, models must not only “think” but also be able to read files, query databases, call tools, and write results back to business systems.
It understood structured output as “making the model articulate in a way machines can directly comprehend” and MCP as “making the model easier to connect with external tools through standard interfaces,” which is closer to real products than merely explaining terms.
The second test involved asking it to write a local command-line tool in Python to manage daily collected AI industry news leads. The prompt was simple, with a few basic constraints: no internet access, no API calls; it should be able to add, view, filter, deduplicate, automatically score news value, and export a markdown daily report.
V4 Pro directly provided a runnable small tool.
Users can input company, title, type, source, link, time, text, and verification status, and the program will automatically calculate the news value score, categorizing leads into “directly quotable,” “needs further verification,” and “not adopted at the moment.” The exported markdown will also be grouped by levels, retaining dimensions like company, title, type, score, and source.

This test illustrates that V4 Pro can decompose a relatively complex intent into structure, rules, and executable code, aligning with DeepSeek’s past user mindset.
On developer channels like OpenRouter, the DeepSeek V3 series has already proven its cost-effectiveness and user inertia.
OpenRouter data shows that the DeepSeek V3 series consumed over 7.27 trillion tokens in 2025, ranking fifth, only behind models like ClaudeSonnet4 and Gemini2.0Flash. Even today, the invocation volume of DeepSeek V3.2 remains among the top on the OpenRouter leaderboard.
This indicates that user recognition is not solely based on benchmarks but on whether a model can perform stably, cheaply, and efficiently in real workflows.
This can also be observed with Claude.
In comparisons between ClaudeOpus4.6 and GPT-5.4 series on various model capability rankings, the conclusions do not always show Claude leading comprehensively; in some knowledge, reasoning, and speed metrics, GPT-5.4 performs better.
However, this has not hindered Claude from continuing to attract developers and enterprise markets. Anthropic disclosed in February this year that, based on its revenue pace at the time, the company’s annual revenue scale had reached $14 billion, with its revenue growing more than tenfold over the past three years.
Thus, to objectively assess a model’s capabilities, one must consider its actual engineering performance in real workflows.
Of course, V4 is not without its shortcomings. The biggest regret is its current lack of native multimodal capabilities. Even before its release, the community’s expectations for V4 extended beyond just a text model. Some media previously reported that DeepSeek V4 was planned to be a multimodal model capable of handling images, videos, and text generation.
The absence of multimodal capabilities indeed presents a real issue; once it involves visual understanding, chart analysis, or handling PPT/webpage/software interfaces, it reaches the model’s capability limits.
Today’s productivity tasks are no longer just about “reading a piece of text.” Many users need to deal with images, tables, screenshots, PDFs, web pages, video conferences, and complex software interfaces. Without native multimodal capabilities, V4 can still serve as a powerful foundation for long tasks, but it is not yet a complete work entry point.
From another perspective, standing at the crossroads of financing and IPO, V4 primarily addresses the foundational issues for its parent company rather than completing the entire structure.
DeepSeek at the Crossroads of Financing
Another backdrop to the V4 release is the sudden influx of financing news surrounding DeepSeek.
Clearly, as a rare species in the Chinese AI industry, DeepSeek has never lacked funding.
In the past, one of DeepSeek’s most recognizable tags was its deviation from the typical AI unicorn narrative driven by financing. Backed by quantitative investment firm Huanfang and with figures like Liang Wenfeng maintaining a mysterious yet focused image in the industry, DeepSeek has been quite unique.
However, recent developments indicate a shift. Latest reports suggest that DeepSeek is seeking financing at a valuation exceeding $20 billion, with companies like Alibaba and Tencent reportedly in talks for investment. The specific figures are still under negotiation, but the direction is clear: DeepSeek has reached a critical point for engaging with the capital market.
And V4 is a crucial lever at this juncture. The efficiency-focused logic behind V4 effectively captures the most concerned aspects of the current developer community, where predictable invocation demands may be further amplified, driving more commercial applications.
This presents the most challenging phase for DeepSeek ahead. The $20 billion valuation must prove that not only is the model strong, but it can also transform into a stable commercial system.
Competitors are already taking action. Qwen, GLM, and Kimi are all moving towards agentic coding, tool invocation, and long task execution, while Claude has made enterprise knowledge work and code workflows its most important commercial focus.
Evidently, leveraging V4’s capabilities, DeepSeek needs more product-level implementations.
An agent cannot operate solely on the foundation model; it also requires a browser, file system, permission system, enterprise software interfaces, plugin ecosystem, and product experience. Even if V4 resolves foundational issues, how to establish a user ecosystem for productivity scenarios is a question that Liang Wenfeng and his team must consider next.
Thus, the most accurate positioning for V4 is not the new species people imagine, but rather an elevation of the “open-source model task foundation” to a new height.
In the past, DeepSeek has already proven that Chinese companies can create strong models at lower costs. V4 must now demonstrate whether this low-cost approach can continue to hold in the coming phase of million-token contexts, agents, domestic computing power, and commercialization.
Currently, V4 has played the efficiency card. The next question for DeepSeek is whether this card can support the commercial scale of a $20 billion company.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.