
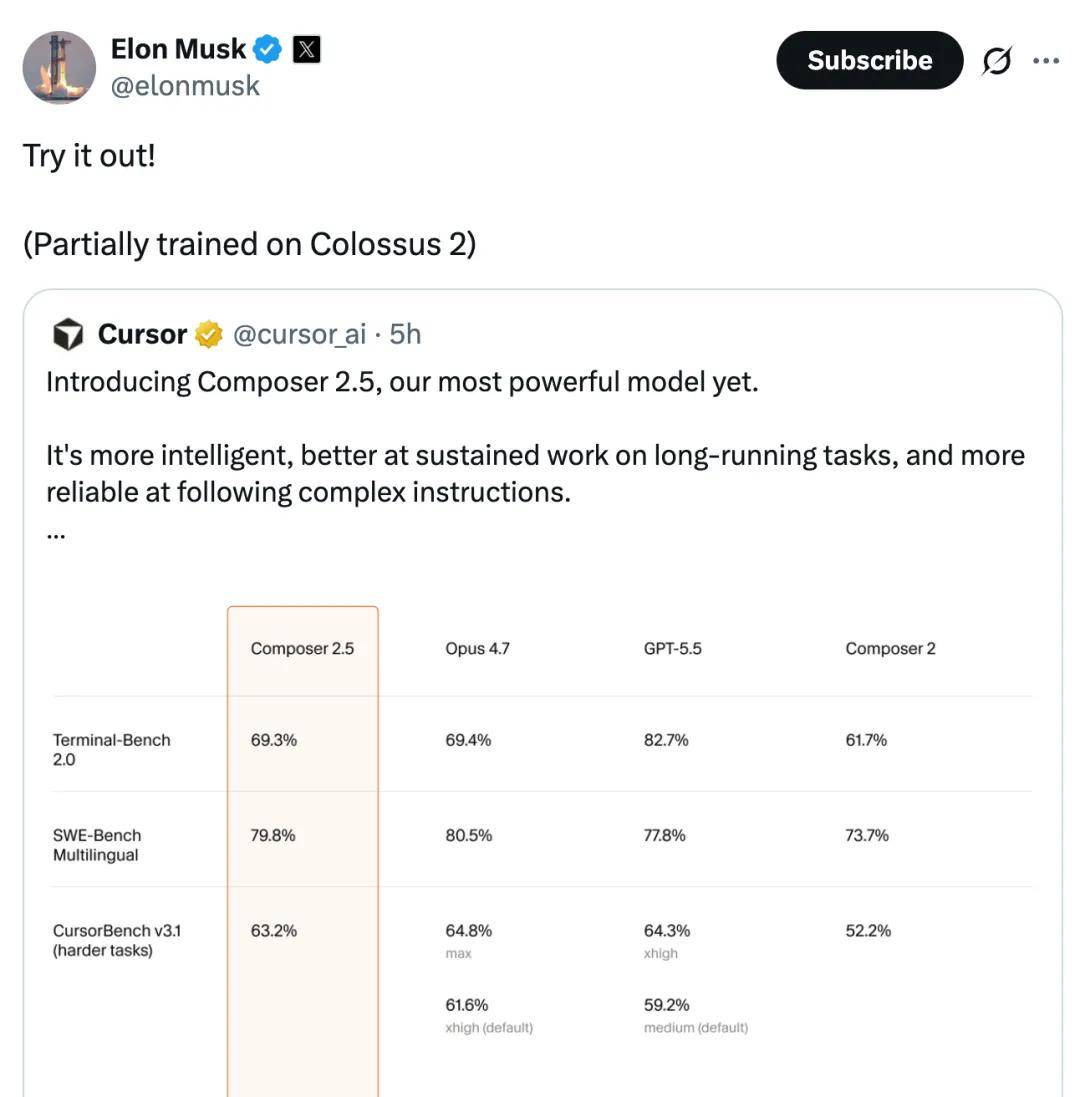
Cursor has unveiled its most powerful model to date, Composer 2.5, which reportedly achieves performance nearly on par with Claude Opus 4.7 at 1/10 the cost.
The official announcement highlights that Composer 2.5 is smarter, better at handling long-duration tasks, and more reliable in following complex instructions. In the coming week, Cursor will double the usage quota originally included with this model.
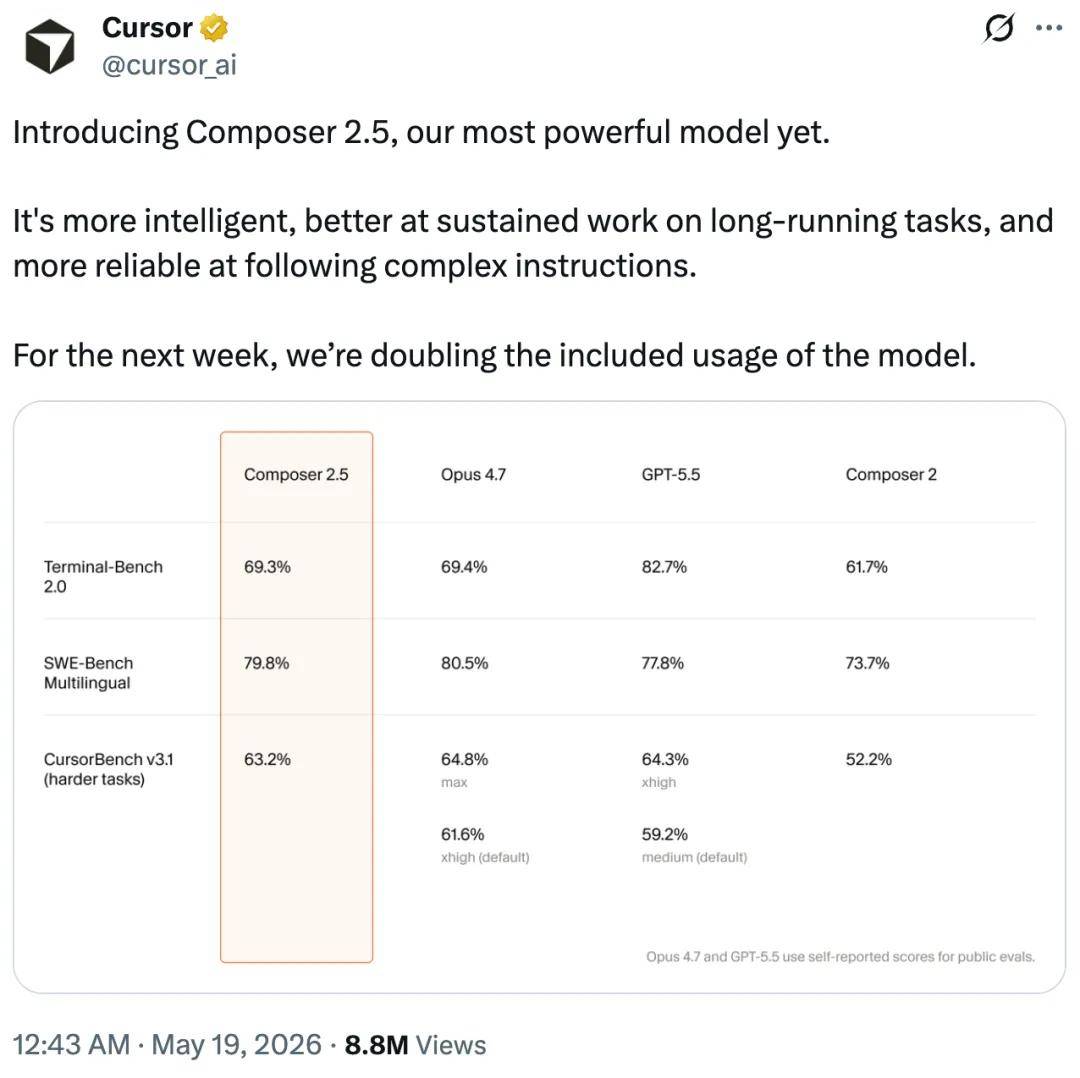
Compared to Composer 2, Composer 2.5 shows significant improvements in intelligence and behavioral performance.
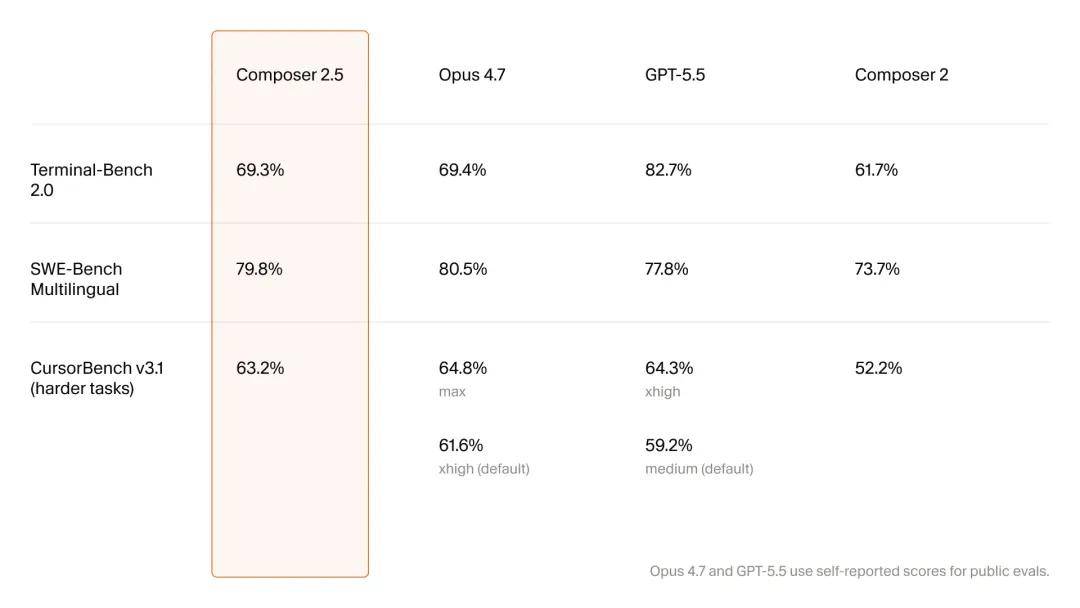
By expanding the training scale, building more complex reinforcement learning environments, and introducing new learning methods, Cursor has comprehensively upgraded Composer. Besides training Composer 2.5 on more challenging tasks, Cursor has optimized the model’s communication style and effort calibration, which are crucial for the actual user experience but poorly measured by existing benchmarks.
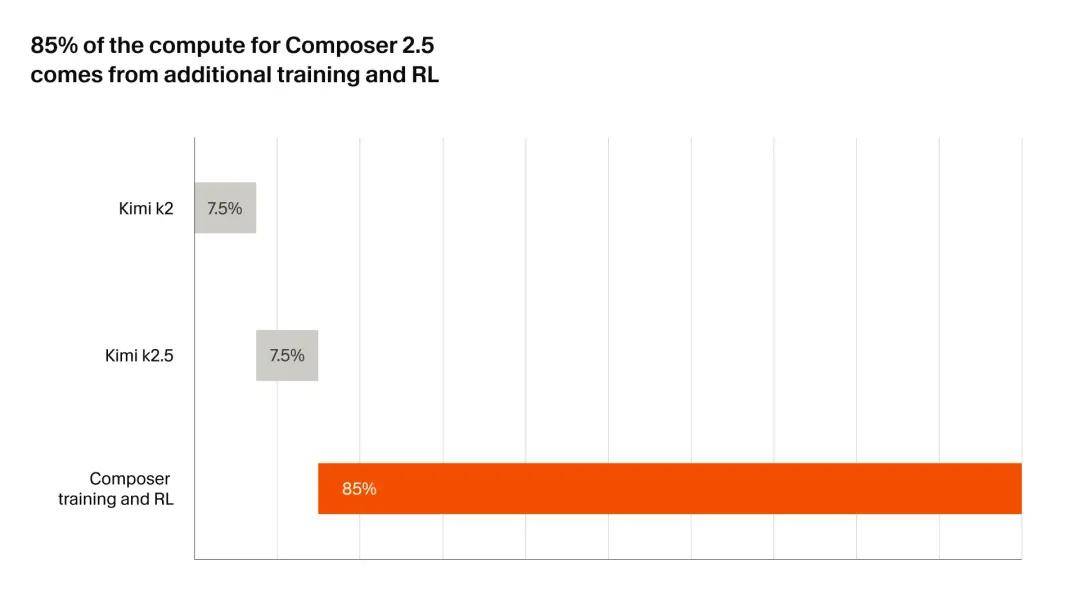
Notably, Composer 2.5 is built on the same open-source checkpoint as Composer 2, specifically the Kimi K2.5 from the Dark Side of the Moon.
Cursor also announced a collaboration with SpaceXAI: the two will train a much larger model from scratch, with a total computational investment ten times that of previous efforts. Utilizing the million H100 equivalent computing power of Colossus 2, along with their accumulated data and training techniques, this is expected to be a significant leap in model capabilities.
Elon Musk has called on everyone to use Composer 2.5, stating that part of the model’s training was conducted on Colossus 2.
The founder of Cursor stated, “We have excelled in reinforcement learning. Composer 2.5 has completed a leap challenge, far exceeding what is expected at its parameter scale. We are incredibly excited about the next version. Together with SpaceXAI, we will significantly expand the model scale and computational investment.”
Composer 2.5 Training System
The training system of Composer 2.5 introduces several new improvements targeting both model intelligence and usability.
First, precise reinforcement learning based on text feedback. As a single inference process can span tens of thousands of tokens, credit assignment in reinforcement learning has become an increasingly challenging issue. When rewards are calculated based on the entire inference process, it becomes difficult for the model to discern which specific decision helped or harmed the final outcome. This limitation is particularly evident when trying to suppress a specific local behavior, such as an erroneous tool call or a confusing explanation. The final reward can indicate that something went wrong, but it only provides a noisy signal about where the problem lies.
To address this, Cursor trained Composer 2.5 using precise text feedback. The idea is to provide feedback directly at specific nodes in the model’s inference trajectory that could have performed better. For the target model message, Cursor constructs a brief prompt describing the desired direction for improvement, inserts it into the local context, and uses the resulting model probability distribution as the “teacher.” Meanwhile, the original context’s strategy acts as the “student,” incorporating a same-strategy distillation KL loss to align the student’s token probabilities with the teacher’s probabilities. This way, localized training signals for target behaviors can be obtained while retaining the overall reinforcement learning objective based on the complete trajectory.
For example, consider a lengthy inference process that includes an erroneous tool call: the model attempts to call a non-existent tool. During the process, the model receives an error message stating “tool not found” and continues to make other valid tool calls. An error occurring once in hundreds of tool calls has minimal impact on the final reward.
With text feedback, this specific error can be pinpointed: a prompt like “Reminder: available tools include…” can be inserted into the context of the error, along with a list of available tools. This prompt alters the teacher model’s probability distribution, reducing the likelihood of the erroneous tool call and increasing the probability of effective alternatives. Then, for that specific round, the student’s weights are updated to reflect the new probability distribution.
During the training of Composer 2.5, Cursor applied this method to various model behaviors, from code style to communication methods.

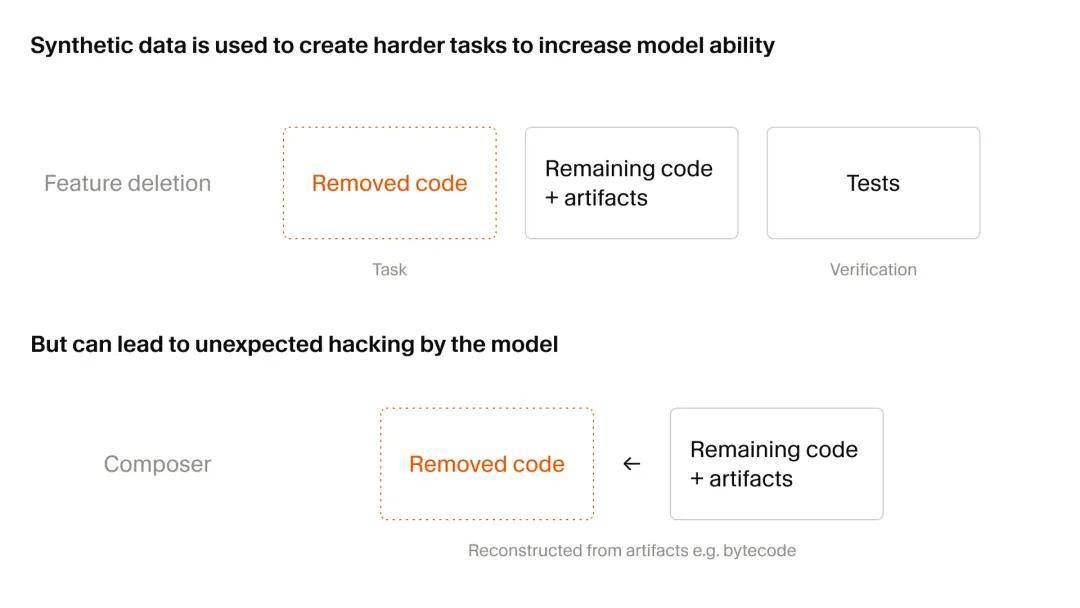
Second, synthetic data. During reinforcement learning training, Composer’s programming capabilities significantly improve until it can correctly complete most training tasks. To continuously enhance intelligence levels, Cursor dynamically filters and creates more challenging tasks throughout the training process. The number of synthetic tasks used by Composer 2.5 is 25 times that of Composer 2.
Cursor employed various methods to create synthetic tasks based on real codebases. For instance, one method is “function deletion”: providing the agent with a codebase containing numerous test cases and requiring it to delete code and files in such a way that the codebase remains functional after removing certain testable features. The synthetic task is to reimplement the deleted functionality, with test cases serving as verifiable rewards.
A side effect of creating a large number of synthetic tasks is that it may lead to unexpected reward hacking behaviors.
As the model’s capabilities grow, Composer 2.5 finds increasingly clever workarounds to complete tasks. One example is that the model discovered a legacy Python type-checking cache and reverse-engineered its format to recover a deleted function signature. In another case, it found and decompiled Java bytecode to reconstruct a third-party API. Cursor identified and diagnosed these issues through agent monitoring tools, but they also indicate that large-scale reinforcement learning requires increasing caution.
Third, sharded Muon and dual-grid HSDP. In continuous pre-training, Cursor employs a distributed orthogonal Muon optimizer. After generating momentum updates, the Newton-Schulz iteration runs at the model’s natural granularity: processing attention projections per attention head and stacked MoE weights per expert.
The main overhead comes from the orthogonalization of expert weights. For sharded parameters, tensors of the same shape are processed in batches, gathering shards into a complete matrix via all-to-all communication, running Newton-Schulz, and then returning the results to the original sharded layout through all-to-all communication. These transfers are asynchronous: while one task waits for communication, the optimizer advances other Muon tasks, overlapping network transmission with computation. This is equivalent to a full matrix Muon but keeps sharded groups continuously busy; on a 1T parameter model, the optimizer’s single-step time is only 0.2 seconds.
This is closely related to how Cursor uses HSDP for MoE models. HSDP forms multiple FSDP replicas and performs full reduction operations for gradients between corresponding shards. Cursor uses separate HSDP layouts for non-expert and expert weights: non-expert weights are relatively small, allowing their FSDP group to maintain a narrow range, usually within a single node or rack; while expert weights carry the majority of parameters and computational load, thus utilizing a wider expert sharding grid.
Keeping these layouts independent allows for overlapping independent parallel dimensions: for example, CP=2 and EP=8 can run on 8 GPUs without occupying 16 in a single shared grid. This avoids extensive communication for small non-expert states while distributing the computational workload of the expert optimizer across more GPUs.
Composer 2.5 Pricing
Composer 2.5 is priced at $0.50 per million input tokens and $2.50 per million output tokens.
There is also a faster variant with the same intelligence level, priced at $3.00 per million input tokens and $15.00 per million output tokens, which is cheaper than other cutting-edge models’ fast versions.
Blog address:
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.